Wake up everyone new Doctor Who trailer dropped
Love seeing the state-sanctioned monopoly that got record profits last year threaten us to use less of the service we pay them for because those record profits apparently didn’t pay for infrastructure.
Hoping to get serious about managing Smolblog properly in the new year. Does anyone recommend any good project management tools/services for open source projects? The GitHub “projects” feature still felt too repo-based, and this will span several repos.
- I don’t know you’re following me.
- I can’t reblog/boost or see your reblogs/boosts.
So why am I even on this server? Because M.b has been around for a few years and I don’t want to move again.
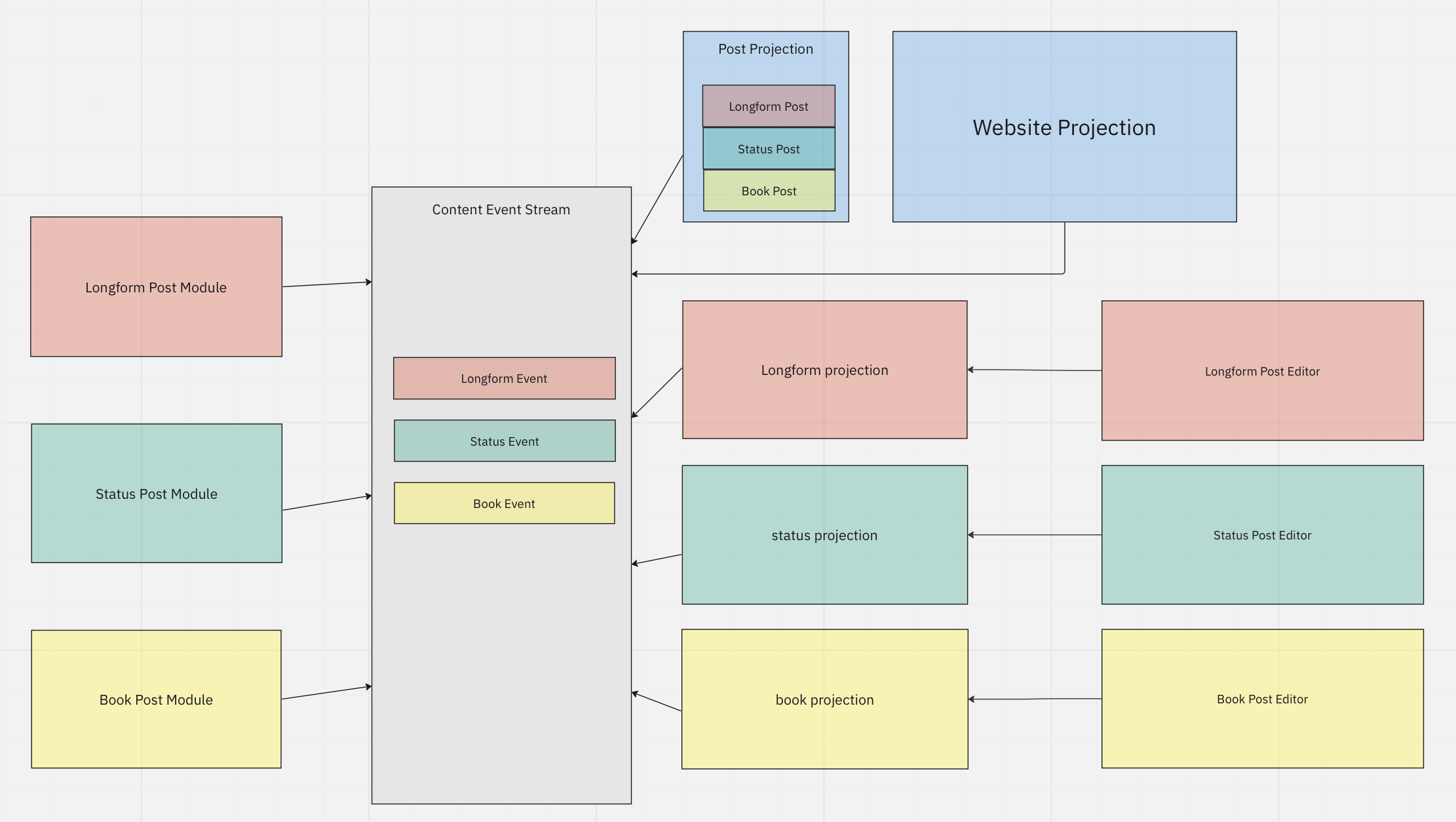
Been working on a diagram of how to get event sourcing to work for a blog with multiple post types. Feedback welcome.
In light of a certain site no longer permitting links to certain other social media sites, I propose we start referring to the federated prehistoric elephant site as “Mufasa.”
This is what it comes to. Argentina scores when I’m not in the house. France scores when I’m in the house. So here I am. Outside. ⚽️

Somehow, my mother-in-law found the 2004 Christmas compilation from now-dead label A Different Drum. So now I’ve got some Christmas music on rotation.

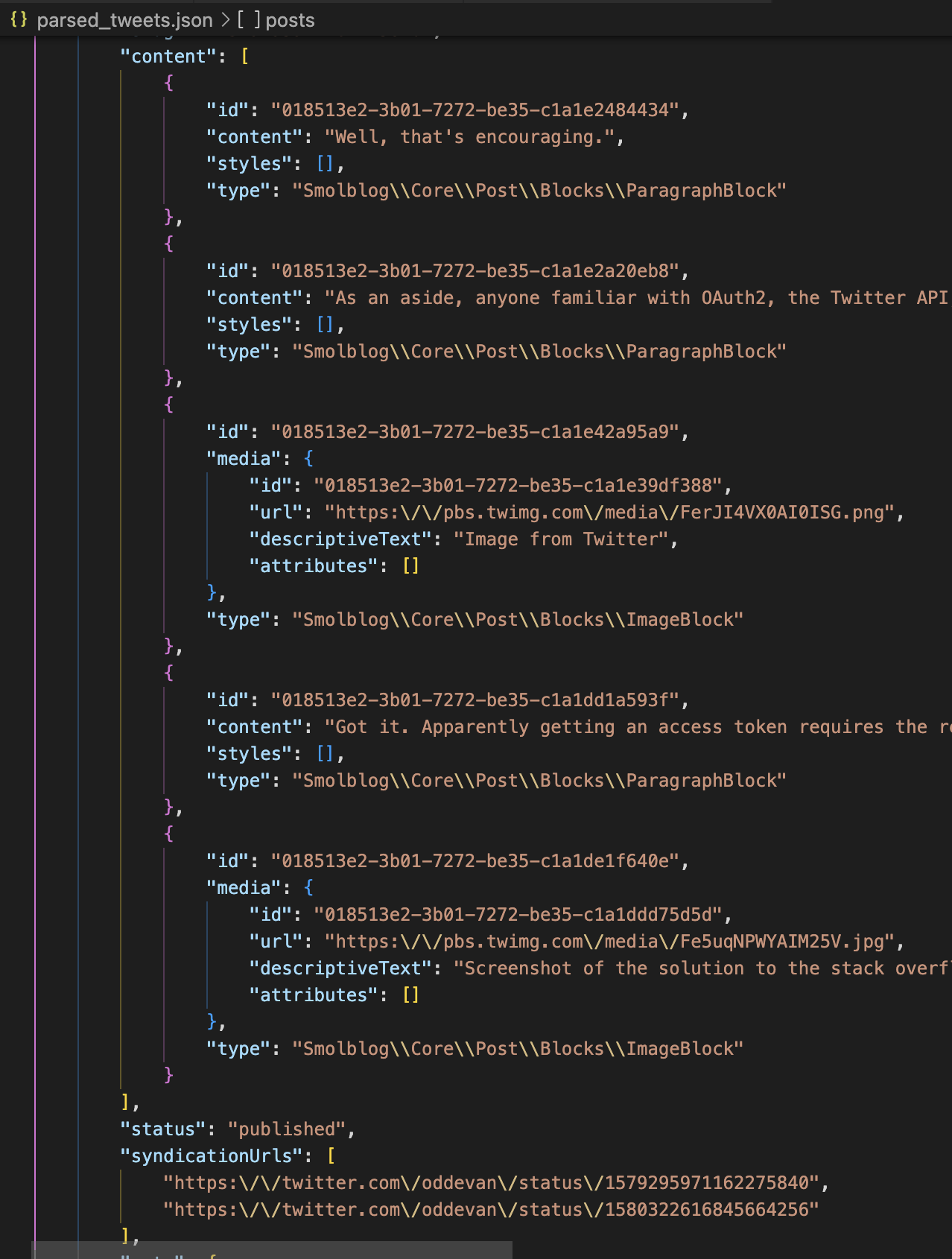
Don’t look now, but I think I might have my Twitter import working with unthreading. (Note the multiple syndicationUrls in the screenshot!)
Thinking about event sourcing as a way of enabling
- A statically generated website with partial regenerations
- An extensible content model that doesn’t rely on (mis)using metadata
- Real-time collaboration
…I’m gonna end up building my own CMS, aren’t I?
If you haven’t heard of Project Mushroom, it’s an online community centered around activism, justice, and how they intersect with Climate Change. They need a bit more on their Kickstarter to make their goal and start going, so check it out!
You’ve heard of a horse in a hospital? Get ready for a goat in a grocery store!
🎵 Gonna ask this again, like I do almost every year: anyone know any good new wave/retro wave/synthpop/EDM Christmas music?
The Mythbusters said that lying down and resting is 90% as good as actual sleep. The day after restarting Vyvanse post-vacation, I desperately need that to be true.
🎵 Okay, what’re the songs that, if you let them, will absolutely make you cry? For me, it’s
- “Walk On” / U2
- “Dare You To Move” / Switchfoot
- “Happy Is a Yuppie Word” / Switchfoot
- “Christmas Don’t Be Late” / Rosie Thomas
…among others.
I love a lot of what Marvel has done, but I loathe their 30-second “look at us” logo that they use like opening titles and not a publisher’s stamp. And of course everyone copies without thinking. Case in point: the new Dreamworks logo.
I tend to frequent a local coffee shop for waffles. Today’s soundtrack as I walked in was “I’m Still Standing,” “Funky Town” as I waited, and “Take On Me” as I left.
This bodes well for today.
Why am I oddEvan?
There were two Evans. Even Evan lived across the hall. He was a very proportional man, had good posture, and always kept the salt with the pepper.
I’m odd.
I’m a web developer. I have, if I’m honest, some pretty good skills in that area. And that tends to give me some unhealthy internal motivation. (I can DIY, therefore I should.)
Feels good to let that go, TBH.
Posted from status.eph.me 😎
And I’m back here.
I’ve been working on my own social media replacement, but with Twitter actively imploding and me cruising towards burnout on the project, I need someplace reliable to be.
Hello, it’s me.
Building Smolblog: Separation
My first exposure to the SOLID principles for object-oriented programming came from the senior developers at the WordPress agency I was working at. It was a bit of a big change to how I had normally approached object-oriented programming. I was used to objects encapsulating broad swaths of functionality related to a particular thing. SOLID demanded that my objects be smaller, more focused, and much more numerous.
SOLID was hard for me to get the hang of, and in reality, I never got the hang of it while I was working for the agency. It felt like overkill: why should I create five different classes and boilerplate a ton of infrastructure just to end up calling register_post_type? Why go to all the trouble of dependency injection when the functions I need to call are right there?
A few months removed from agency work (and knee-deep in the Ruby world), I’m finally starting to get it. And in a way, I was right: it is overkill… if I’m only building a WordPress plugin.
But Smolblog is not only a WordPress plugin.
SOLID-ly Overkill
SOLID is an acronym which stands for five principles of object-oriented programming:
- Each class has a single responsibility.
- A class is open to use by others but closed to changes.
- A class can be replaced by any of its subclasses according to the Liskov Substitution Principle.
- A class' interface is a promise to other classes to behave a certain way.
- A class' dependencies should be given to it according to the other principles.
Points 2, 3, and 4 are ideas I take for granted. Classes have public and private properties and functions, and while the private aspects can change as much as anyone wants, the public aspects are a contract with the rest of the program. And interfaces and inheritance are amazing ways to keep similar logic in one place and change things where they’re different. I learned this back in my C++ days. No big.
It was the first and last points that tripped me up, badly. My idea of a single responsibility was “This class handles everything to do with this thing.” The seniors said a single responsibility was “This class handles this one task.” I thought that sounded more like a function. I also struggled with dependency injection. What was the point of encapsulating logic inside of an object if you had to give the object the logic?
Trying to implement these principles just to create a post type simply wasn’t worth it. It made the code bigger and more complex than it needed to be. Combined with the fact that there were no real testing practices in place meant that trying to code fully-idealized SOLID code felt like all of the hassle and none of the payoff.
What the senior devs were aiming for was more than a couple of hooks; it was a future of much more complex functionality that would need to be picked up by a rotating squad of developers. It was a potential for writing tests on client-specific business logic.
SOLID principles aren’t overkill when you’re building an application; they’re essential.
Stop Trying To Do Everything
The first hurdle I had to get over was personal. I’m a people pleaser. I want to do everything for everyone all the time so that maybe people will like me. What I didn’t realize was that (toxic) idea had spread to my coding style: my “everything” classes were made in my own image.
I wanted to encapsulate logic into neat little packages that I could hide from the rest of the application. For example, I would want creating a new post to be (essentially) one line of code:
$post = new Post(
id: null,
title: 'My first blog post!',
author_id: 5,
content: 'This is so cool, I wish I knew how to blog.'
);
Behind the scenes, though, there would be too much happening:
class Post {
function __construct(
$id,
$title,
$author_id,
$content,
) {
global $db;
if (
!isset($title) ||
empty($title) ||
!isset($content) ||
empty($content) ||
!isset($author_id) ||
$author_id <= 0
) {
throw new Exception('Bad post data!');
}
if (isset($id)) {
$id = $db->query(
"UPDATE `posts` SET `title`=?, `author_id`=?, `content`=? WHERE `id`=?",
$title,
$author_id,
$content,
$id
);
} else {
$db->query(
"INSERT INTO `posts` SET `title`=?, `author_id`=?, `content`=?",
$title,
$author_id,
$content
);
}
$this->id = $id;
$this->title = $title;
$this->author = $db->query('SELECT * FROM `users` WHERE id=?', $author_id);
$this->content = $content;
}
// Other helper methods and such...
}
This pretend class is written with these requirements:
- Every
Postobject should correspond to something in the database. - Every
Postobject should have a title, author, and content. - Every
Postobject should have an ID; we can infer that a new post will not have an ID and get one when the post is created in the database.
Right off the bat, though, we’ve coded some big assumptions into our class:
- The global
$dbobject exists. - The global
$dbobject has a query method. - Posts are stored in the
poststable. - Authors are stored in the
userstable.
Here’s the thing that took me so long to grok: even though these assumptions are probably true now, they may not be true later. On some level I understood this, but I figured if that day came I would spend a day pouring through the codebase making the necessary changes.
People pleaser, remember?
If we were to make this code more SOLID, we’d have a few different classes. First, we’ll pare down the Post class to just one responsibility: data integrity. If the class is given bad data, it should not create the object. So now our class can look like this:
class Post {
function __construct(
?int $id = null,
string $title,
Author $author,
string $content,
) {
if (
empty($title) ||
empty($content)
) {
throw new Exception('Bad post data!');
}
$this->id = $id;
$this->title = $title;
$this->author = $author;
$this->content = $content;
}
// Get/set methods...
}
Not only did we take out all the database code, we also added type hints to the constructor’s parameters. This way, PHP itself can check if title, author, and content are set and throw an error if not.
Saving $post to the database and turning some author_id into an Author object with data are not the responsibility of a Post.
Creating a Dependency
Let’s go back to our hypothetical post creation and put that code in context. We’ll say we’re getting a request through the API to create a new post. With our old do-everything Post class, that endpoint class could look like this:
class NewPostApiEndpoint {
public function __construct() {}
public function run(WebRequest $request) {
$post = new Post(
id: $request['id'] ?? null,
title: $request['title'],
author_id: $request['author_id'],
content: $request['content'],
);
return new WebResponse(200, $post);
}
}
Short, sweet, and to-the-point. Beautiful. Except now we know what horrors once lied beneath that innocuous new Post call. We could bring all those database calls into our endpoint class, but that wouldn’t fix the underlying issue: what happens when the database needs to change?
Really, the first question we should ask is, “What is the responsibility of NewPostApiEndpoint?” Our short-and-sweet class helps us answer that question: to save a Post with the data from the web request.
What’s not included: knowing how the Post is stored. “But we know it’s a database!” Yes, we know it’s a database; the class should only know what it needs to do its job. So let’s start writing our new endpoint but leave comments where we have missing information:
class NewPostApiEndpoint {
public function __construct() {}
public function run(WebRequest $request) {
$post = new Post(
id: $request['id'] ?? null,
title: $request['title'],
author: // TODO We have author_id, need object
content: $request['content'],
);
// TODO Have post, need to save
return new WebResponse(200, $post);
}
}
We’ve identified two outside responsibilities: getting an Author object and saving a Post object. Those sound like single responsibilities to me!
Here’s where the power comes in: our endpoint object doesn’t need a specific object for these jobs, just an object that can do the job. So instead of writing new classes, we’ll create two interfaces:
interface AuthorGetter {
public function getAuthor(int $author_id): Author;
}
interface PostSaver {
public function savePost(Post $post): void;
}
Now that we have those interfaces defined, we can finish our endpoint:
class NewPostApiEndpoint {
public function __construct(
private AuthorGetter $authors,
private PostSaver $posts,
) {}
public function run(WebRequest $request) {
$post = new Post(
id: $request['id'] ?? null,
title: $request['title'],
author: $authors->getAuthor($author_id),
content: $request['content'],
);
$posts->savePost($post);
return new WebResponse(200, $post);
}
}
And that’s Dependency Injection in a nutshell! Cool, right?
Yeah…except, again, we’ve only moved the complexity. We still have to make those database calls at some point. And when it comes time to finally assemble the application, we have to keep track of what classes have which dependency, and… ugh.
Can’t See the Trees For the Forest
This was my other problem with the SOLID principles: how is Dependency Injection supposed to actually make things easier? I understood the idea of passing in what an object needs, but I got overwhelmed trying to picture doing that for an entire application. Trying to keep track of all of all the dependencies for an object also meant keeping track of those dependencies' dependencies, and it didn’t take long for the infinite recursion to crash my brain.
What I failed to grasp was that knowing objects' dependencies counts as a single responsibility. So why not let computers do what they do best?
The established pattern here is known as a Dependency Injection Container. The PHP Framework Interop Group has an established interface for these containers that is widely accepted across the industry. These objects store a mapping of classes and dependencies and create properly-initialized objects.
To complete our example, we’ll use the Container package from The League Of Extraordinary Packages:
use League\Container\Container;
$container = new Container();
$container->add(NewPostApiEndpoint::class)
->addArgument(AuthorGetter::class)
->addArgument(PostSaver::class);
// Later on...
$newPostEndpoint = $container->get(NewPostApiEndpoint::class);
And that’s pretty much it! We set up our classes to accept the dependencies they need, then we set up the container to get those dependencies to the classes. If those dependencies have dependencies, the container will take care of them too.
The only thing we have left to do is actually set up our two dependencies. We added the interfaces as arguments, but we haven’t given any concrete implementations to the container. We’ll skip writing out those classes and just show how it could work here:
$container->add(AuthorRepo::class)
->addArgument(DbConnector::class);
$container->add(PostRepo::class)
->addArgument(DbConnector::class);
$container->add(AuthorGetter::class, AuthorRepo::class);
$container->add(PostSaver::class, PostRepo::class);
This tells our container that that anything that depends on AuthorGetter should be given an instance of AuthorRepo, and anything that needs PostSaver should be given PostRepo.
But why go to all this trouble? We’ve taken a few lines of code and spread them out over three classes (five if you count the interfaces) and introduced an entirely new library to our code. While the individual pieces of the code may be easier to follow, the flow of code through the entire application is now much more complex. What does all this extra work actually get us?
Know What You (Don’t) Need
I could say “it makes things easier to change” and leave it at that. By isolating different responsibilities in the code, it’s easier to find and change that specific code when circumstances change (which they inevitably will). But this truth can be hard to visualize when those changes seem unlikely.
I’m writing about these principles because I’m using them to rewrite Smolblog. The version currently running here is a WordPress plugin top-to-bottom, albeit with some efforts at SOLID principles. It gets the job done, but it doesn’t feel maintainable. There’s a lot of code that should be abstracted out, but I didn’t see a good way to.
For the rewrite, my guiding principle was “leave your options open.” I wasn’t sure what was going to be best for Smolblog in the long term despite feeling very sure that WordPress was the best option in the short term. I didn’t want to box Smolblog into using WordPress longer than it needed to, but I also didn’t want to bet on a PHP framework only to discover it was a bad fit and have to rewrite large swaths of code again.
About a month into the rewrite I realized I had stumbled backwards into SOLID programming. In order to isolate my code from the outside platform, I had to write interfaces for anything I needed from the platform. I started with several overly-complicated setups before everything finally clicked enough to…
Well, it’s clicked enough that I finally feel confident enough to write this blog post and introduce you to Smolblog\Core. This is where all of the Smolblog-y logic will be that makes Smolblog what it is. And the single biggest change is that while the code still depends on an outside platform, that platform doesn’t have to be WordPress.
There’s more complexity here, sure. Version one has just under 1600 lines of code while Smolblog\Core has 1800, and it can’t do everything version one can yet! But with that added complexity comes a better separation of concerns.
In the container example above, I noted that we could define interfaces in one area then set the concrete implementations in another. That’s the principle I’m using to keep the WordPress-specific code separate from the core code. This way, the WordPress-backed PostSaver class might look something like this:
class WordPressPostSaver implements PostSaver {
public function savePost(Post $post): void {
wp_insert_post(
'id' => $post->id ?? 0,
'post_title' => $post->title,
// et cetera...
);
}
}
One that used the database directly could look more like this:
class DatabasePostSaver implements PostSaver {
//...
public function savePost(Post $post): void {
$this->db->query(
"INSERT INTO `posts` SET `title`=?, `author_id`=?, `content`=?",
$post->title,
$post->author->id,
$post->content
);
}
}
And because of the abstractions we’re using (namely the PostSaver interface), nothing else has to change.
Smolblog is still being built on top of WordPress. This time, though, all of the WordPress-specific code is in its own project. All of the WordPress idioms and functions get passed through their own set of classes to match the interfaces that Smolblog requires.
Now, instead of different WordPress functions being sprinkled throughout the project, they’re centralized and cataloged. We know what Smolblog can do and what it needs WordPress (or some other framework) to do.
SOLID-ly understood
I genuinely think part of the reason SOLID never clicked for me at the agency was the simple fact that we were always going to be using WordPress. I didn’t see a difference between using a WordPress function and using a built-in PHP function; both were always going to be there, so why bother isolating them as a dependency? Now that I’m working on a project—a big one!—that doesn’t have that constraint, I’m beginning to see the value even if we were staying with WordPress.
I still maintain that if you know the plugin will never be more than a few calls to WordPress-specific functionality, like custom post types and taxonomies, then it’s best to use some namespaces and just get the job done. But I should also admit that it’s taken a lot of experience to know which is which.
It’s not lost on me that at some point in this project I’ll have 90% of a framework for using these principles in a WordPress plugin if not 90% of a framework in general. Combining these principles with Domain-Driven Design and Command-Query Responsibility Separation almost guarantees it… but that’s another blog post.
For now, I’ll just go ahead and admit it: y’all were right. As usual.
Building Smolblog: Open
I’ve been meaning to blog more as I’ve been working on the actual Smolblog code. And, with one of my other side projects finally shipping, I feel like I can start putting down some thoughts here. So here I am.
And the first thing I want to talk about isn’t just code, it’s about what specific words mean. I specifically want to start with something that isn’t a programming or coding problem. It’s really easy for us developers to try to solve all sorts of problems with code. But while well-built software in the right hands can do amazing things, the biggest problems we will solve are social, not technical.
So when I say I want Smolblog to be “open,” this is a question that is more social than technical.
You Know What Else Means Open?
Lots of things like to say that they are “open.” Google repeatedly calls Android open. Epic games has been called “champions for a free and open internet." Cryptocurrency and blockchain projects are often touted as decentralized and open. And WordPress, the system that Smolblog is currently using as a foundation, is famously open. But these all mean different things.
Epic Games advocates for free and open systems where anyone can install anything they want, especially their own Epic Games Store. That store, at least currently, does not have the freedom for anyone to sell whatever they want. By the same token, Android is a freely downloadable project that can be used by any phone manufacturer, but it is heavily tied to the Google Play store that has its own approval process. And while anyone can get into cryptocurrency and make transactions, the resources required to actually participate in “mining” on popular blockchains are prohibitive to all but a few.
So when I say Smolblog is open, what do I mean? How about this:
Smolblog’s Definition Of Open
- The Smolblog software is freely available to use, modify, and share.
- Interactions do not require blogs or users to be on the same instance of the Smolblog software.
- Users can reasonably expect to take their data from one instance of the Smolblog software to another with no change in functionality.
A Brief Aside About Free and/or Open Source
The first point is one well-known in the software world. It corresponds to the freedoms championed by Free Software and Open Source advocates. Though the two groups have philosophical differences, they agree in practice: software should be free to use, free to change, and free to share (both modified and unmodified).
This is often found in libraries, frameworks, and infrastructure for web apps. Most web apps are written in scripting languages where there is no way to run the app without having the source code. And as companies base more and more of their existence on the web, the level of control that freely usable and modifiable software provides is essential.
While the source code is available for free, and anyone can search on their preferred search engine for help, companies with the budget to do so often buy official support from the vendor. Vendors often also provide fully-hosted versions of their products as a subscription offering. Discourse and Gitlab are two examples of projects like this.
This approach hasn’t worked for everyone, though. Elasticsearch used to be a project with Open Source and an official hosted solution. However, in the mid-2010s, their paid hosting was undercut by other vendors that offered the open source project on their systems, not Elastic’s. Elastic eventually changed their license to prohibit this, but in doing so violated the “freedom to use.”
While I don’t envy Elastic (and other similar companies) for the decisions they had to make, it highlights the key tradeoff of Free Software: the freedoms apply to everyone, including competitors. If Smolblog is going to be an open system, it has to be open for everyone. Any plan to make money from Smolblog has to take this into account.
How Do We Want To Do This?
First, some technical background. Smolblog is currently using WordPress as its foundation. I use those specific words because while Smolblog currently exists as a WordPress plugin, it is being built as its own product. Not everything in WordPress may be used or supported by Smolblog in the long term, but by making use of WordPress Smolblog is able to be a complete product sooner.
So, for our definition of open, we have three basic pillars: software, interactions, and data. Let’s tackle them in reverse order.
Open Data
This is a technical problem, and a relatively easy one at that. Most systems and web apps have a way of exporting a user’s data for download. This has been helped along by privacy laws in some parts of the world.
Smolblog will need a feature that allows users to download their data in a standard format. Smolblog will also need a feature that allows users to upload their data export.
This feature should be as self-contained as possible. The downloaded export should contain everything needed to load the data into a new server with minimal setup. This includes not just posts and images but also information on connected social media accounts and plugin-specific data. Another Smolblog server should be able to take this dowloaded export and re-create the user’s data from it.
By making this feature robust, it would provide end-users the freedom to leave a server for whatever reason they need, whether social, technical, or financial. It would also provide server maintainers the social freedom to remove unwanted users: with easy data portability, removing a user becomes less a case of “freedom of speech” and more a case of “should this speech be on this platform?”
WordPress currently has basic functionality in this area, but based on my time in a professional WordPress agency, it lacks the robustness this feature would require.
Open Interactions
Smolblog is intended to be as personal as a blog and as fun as social media. Part of social media’s appeal is the ease of interactions between people, such as replies or likes.
Smolblog features involving interactions will need to work identically whether the blogs are on the same server or different servers. No core features should rely on a central server.
The clearest example I can give of this is email. No single company “owns” email. Email works the same whether a user is on Gmail, Outlook, or iCloud (extensions, plugins, and other add-ons not withstanding). Most importantly, emails can be sent between users on the same server (bob@gmail.com to alice@gmail.com) or users on different servers (bob@outlook.com to alice@icloud.com).
Social interactions on Smolblog need to work the same way. A blog on smolblog.com needs to be able to interact with a self-hosted blog (say, oddevan.com) just as easily as another blog on smolblog.com. We don’t know what these interactions will look like yet, but this will be a requirement.
Some interactions, like following and reblogging, can be handled through existing standards like RSS/JSONfeed and oEmbed. This can open these features beyond Smolblog and extend Smolblog’s “openness” to other sites and apps.
Open Source™
This is more than just making the source code available. To embrace this as a principle and not just a bullet-point, Smolblog needs to not only have an Open Source license but be written in a way that is truly open.
The majority of the Smolblog project will be released with a strong copyleft license. Exemptions to this can be made in the interest of supporting the project and its openness.
I see three tiers to this:
Tier One: Copyleft through the GNU Affero General Public License
The Affero General Public License (AGPL) is possibly the strongest (or most restrictive) open source license. It requires the full source code of the application to be made available for sharing and modification to all users of the application, including users that only use it as a web app. It is called a “copyleft” license because any changes or derivative works must also be covered by the AGPL. For most cases, this will ensure that a Smolblog user can get not just the “official” source code but the source code to the specific server they are on.
WordPress currently uses an older copyleft license that provides most of these freedoms, but there is one key exception. Code for a web app is never “distributed” to its users, only those running the server. Automattic, the company behind WordPress, is able to use this exception to make products using WordPress like P2 exclusive to their own services. While they say they are committed to data portability and open source (and they have been), the ElasticSearch feud has shown that many companies will do everything they legally can.
We want to avoid any Smolblog or Smolblog-derived products from falling into this trap. The AGPL provides legal coverage for this.
Tier Two: Permissive through the Apache License
Licenses that do not require derivative works to be covered by the same license are sometimes called “permissive” licenses. These are especially useful for libraries and frameworks since they can be used by developers in commercial or private projects without involving the company lawyers.
Some of the code written for Smolblog will have a general purpose outside of the project. These could include tools for working with a social media site’s API, a library for putting data into a standard format, or a framework that enables a particular programming style. As part of being in a community of developers, sharing this code with a permissive license will enable Smolblog to benefit people beyond its users.
The Apache License is a recommended permissive license as it includes permissions and rights related to software patents.
Tier Three: Proprietary through individual commercial licenses
Wait, what? Hear me out.
This comes back to the definition of “open” I mentioned at the beginning. Smolblog being open means data portability and decentralized interactions as much as it means Open Source. Of those three principles, Open Source is the one least valuable to the average user (despite its necessity for the other two). There may be times where compromising a little on Open Source can enable uses for Smolblog that make it useful for even more people.
I don’t expect these situations to manifest anytime soon if ever. But putting this option on the table now means that anyone contributing to Smolblog’s source code is aware of it and can agree to it. Asking contributors to assign full copyright to their contributions, while reasonable, has the potential for abuse. Instead, I would prefer that any contribution agreement for Smolblog list the ways the contribution can be used.
One benefit to commercial licenses is being able to custom-tailor them to each business. For example, say a hosting business wants to offer managed Smolblog hosting. Their “secret sauce” is a caching layer that requires a custom-built plugin. This plugin wouldn’t enable any user-facing features, and it would not work without the host’s custom software. This business could get a commercial license limited to their integration code that would exempt their plugin from the AGPL requirements in exchange for a commission on their Smolblog service.
I choose these two examples specifically: Licensing Smolblog under the AGPL is intended to prevent someone building a product or feature locked to a specific provider. Users of Automattic’s P2 cannot move to a different WordPress and keep the same experience; the data is not truly portable in that sense. The hosting company example does not involve any impact to true data portability or use, since the user experience (and the data created by the users) is indistinguishable from the main project. The openness of Smolblog is not impacted in any meaningful way, and the project gets a source of funding that is not dependent on user-hostile advertising.
But as I said, this is all philosophy. None of it matters until Smolblog is actually built. And so we build. You’re welcome to join along.
Take care of each other; I’ll see you next time.
Calling Long Distance
Hey, it’s Evan…
Oh, hey! Listen, I can’t answer the phone right now, but if you leave your name, number, and a message, I’ll call you right back. Thanks!
My first voicemail greeting
Evan! It’s… me? You? There’s time travel involved. Or something. But it’s 2022 right now and… I need you to know something. Something I wish I had learned 20 years ago, so I’m telling you.
You are being lied to.
(I mean, the alarmists and Bush’s haters do have a point, but I’m not talking about Iraq.)
No, this is much more insidious than that. This lie goes back generations, over a thousand years. It is a lie almost as old as Christianity itself.
Because if you can’t stop a revolution, you co-opt it. You twist it so that even though things are changing, even though there’s massive upheaval, you still have what you want.
Why did the Rich Young Ruler go away sad? Because he didn’t want to give up what he had: his comfort, his possessions, his status.
And why were Jesus’ followers so disappointed in him? Because he wasn’t going to put the Jews back over the Romans. He was all about having the Jews and the oppressed force their oppressors to see them as human. That’s where the shirt and coat thing, that’s where the “turn the other cheek” thing comes from: it’s not being passive, it’s forcing the person to see what they are doing to you, what their group is doing to you.
And for a little while, we got it. Look at the first few chapters of Acts, how they took care of each other, sharing what they had and giving what others needed.
And how there was no room for hoarding possessions there, because hoarding what you didn’t need was antithetical to the Gospel. And there was no room for amassing power because we’re all equal in the eyes of God.
And this was a movement, a revolution. It was an idea. It wasn’t something you could stop by killing someone. Or even lots of people.
Now, I want to make my metaphor clear here: being rich, as in the Rich Young Ruler, is about hoarding. It’s about having more money than you need to live or even be comfortable. It can also be about power, about influence, about authority. It’s about having so much of those that others have to go without because of you.
The disparity between the rich and poor is really bad in my time, but I think it’s still pretty bad in yours. Look at how many people don’t have food, shelter, basic needs, and then look at how many rental properties sit vacant. I know you’re not a fan of welfare, but look at how someone can still be working and need welfare. And then look at how much the owners of that company make.
But it’s not just that! Look at those in authority: how much of what they do is taking care of people, and how much is to bolster their own authority? How many with influence and prestige hesitate to use it for fear of losing it?
And that brings us back to the lie. It didn’t start with Emperor Constantine, but he sure codified it. And it’s infested and grown and latched onto and leeched off of the Church, and it’s been cut back at times but it’s clever and it’s insidious and it finds new ways to bury itself in us, and you are not immune. You are not immune to it!
It has fully infested your culture. I don’t mean the culture you are ”fighting” against; I mean the culture of church-going, praise-and-worship-music-business, family-friendly media, end-times-are-coming ”Christianity.” It is a culture, same as everything else.
And that culture will tell you that a camel can pass through the eye of a needle if it contorts itself juuuuuuust right. And that is a damnable lie.
You cannot follow Jesus while seeking power, seeking influence, seeking wealth, seeking authority. You cannot. Anyone who says otherwise is selling something.
You would wear The Ring to try to do good, and it will only corrupt you.
Jesus didn’t tell us to watch out for creating dependency. He told us to help the poor. He didn’t tell us to keep from rewarding sinful behavior. He told us to help our neighbors, no matter who they are. He didn’t tell us to fight a culture war. He told us to love our enemies. And you know this. You know all of this.
And I am begging you now, put that into practice. And do it fearlessly. Don’t worry about being the ”right” kind of Christian; just be Christ-like. Don’t conflate morality and outward appearance with where someone’s heart is. I’m going to say this again, because you need to hear this the most: there are more Christians around you than you realize because you currently have a very narrow view of what a ”Christian” is.
Every person is a person, even if they’re straight or gay, conservative or liberal, attend the “right” church or ”wrong” church or no church at all, whether they’re squeaky clean or curse like a sailor. Everyone is someone, and they all have something to teach you. I’m begging you not to be closed to that.
Listen, I know how important it is for you to get the right answers, I know how much you want to do the right thing. That’s not a bad thing. But it is causing you to see enemies where there are none. And it’s keeping you from listening to and being changed by and truly loving your friends. Your neighbors.
Now, I’m not saying you’re being deliberately lied to. But when that ancient lie has infested so much of what you’ve learned, then everything you know is wrong.
You don’t believe me. Why would you? I mean, Jesus himself said a call like this is useless. So no, I don’t think this is going to change anything, at least for us. Maybe it’ll plant a seed somewhere, though. Maybe there’s someone in my time that needs to hear this just as much as you.
So I’ll leave you with this: watch out for grouping and judging a mass of people. Gay people, liberals, pro-choice women, feminists, poor people, immigrants, migrants, Catholics; remember that everything you say and believe about them affects actual, individual people. People that you know or will know.
And it is neither weakness nor unfaithfulness to have your convictions changed because you love your neighbor.
Because with grace, with forgiveness, with love, there is no ”us” and ”them”; there’s only you and your neighbors.
So love God, and love your neighbor. Everything else—everything else—is extra.
…hey, I gotta go. I’m running out of change. Just know there’s a lot of things that if I could, I’d rearrange.
Introducing Grimoire
TL;DR: I'm building Deckbox but for Pokémon cards. Headless WordPress app with a Next.js/React frontend. You can browse the catalog now; you can also request a beta invite if you want to try it out. Want to learn more? Read on!
My first job out of college was for Blackbaud working on their next-generation platform. It was a software-as-a-service built with an API-first design: every action taken by a user, even through the official app, went through the API. During my time there, the primary app went from a Windows application to a Javascript application (something that made my Mac-loving heart happy), and this was possible because the user interface was decoupled from the application logic.
I think this architecture has stuck with me more than I realized. As headless WordPress took off, I had the chance to learn how to properly build a API-based application. Now all I needed was a problem to solve...
A problem like the massive amount of Pokémon cards in my collection. I've started selling some of them on TCGplayer, and while they have a decent app, it didn't quite fit my needs. I needed an application I could store my catalog in and quickly check it for cards that have increased in value. It also needed to be able to tag different versions of the same card for when it came time to build a deck.
I'd worked on something for this before, even wrote a blog post about it, but now it's time to finish the job. To that end, let me introduce Grimoire.
Yeah, it doesn't look like much. In the interest of finishing, this is a minimally viable product. In this case, lots of Bootstrap. But let me show you what there is!
The Features
One one level, Grimoire is just a catalog of Pokémon cards. It uses the TCGplayer API to get the different cards. TCGplayer is already invested in having an extensive catalog of all the Pokémon cards printed, so that is thankfully work I do not have to do. For Grimoire, I wanted to add two things to their catalog:
Unique, Discoverable IDs
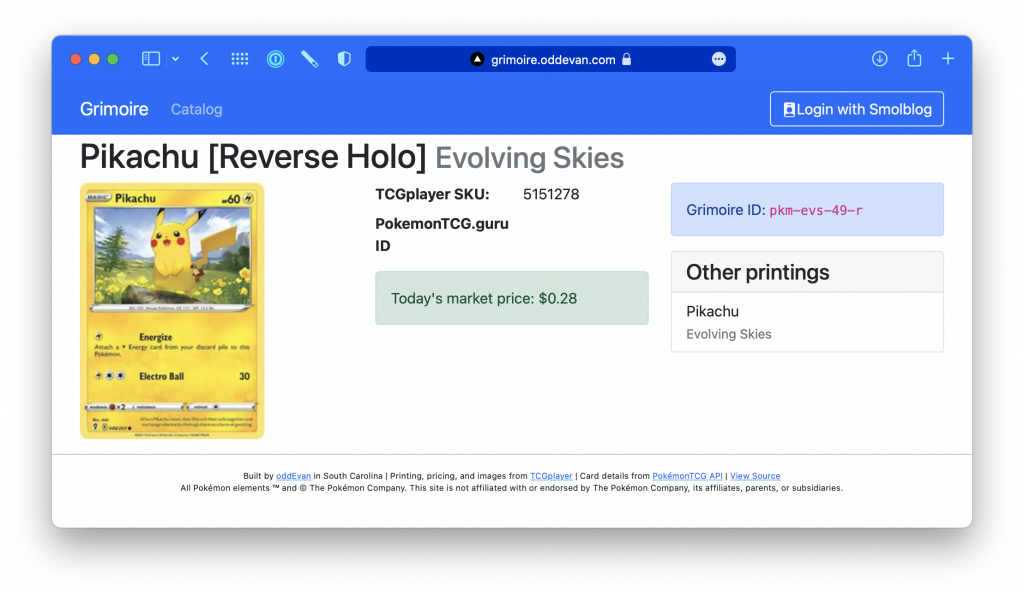
A Grimoire ID (pkm-evs-49-r in the screenshot) consists of up to 4 parts:
- The game the card is from. In this case,
pkmdenotes a Pokémon card. This part is mostly in place for when I inevitably support for Magic the Gathering. - The set the card is from. This card is from the Evolving Skies set, so it's abbreviated
evs. - The card number, including any descriptors and ignoring any total numbers.
- One last part for any extra modifiers that are not part of the card number. The card in the screenshot is a reverse holographic printing, so its ID has an extra
r.
The idea is that by looking at the card, you can infer the ID as long as you know the patterns. This is the part of the project that's going to take the longest, as there is a major manual process to all this. Most cards can fit in this pattern, but there are always exceptions. There are deck-exclusive variants, league staff variants, and a bunch of other cards that will have to be manually assigned IDs.
It's okay. It's not like I have a full-time job or anything.
Identify Alternate Printings
The card in the screenshot above is a reverse-holographic printing. There's also a normal, non-holographic printing. These cards are the same from a gameplay perspective, but they have different collection values. With Grimoire, alternate printings are all linked together:
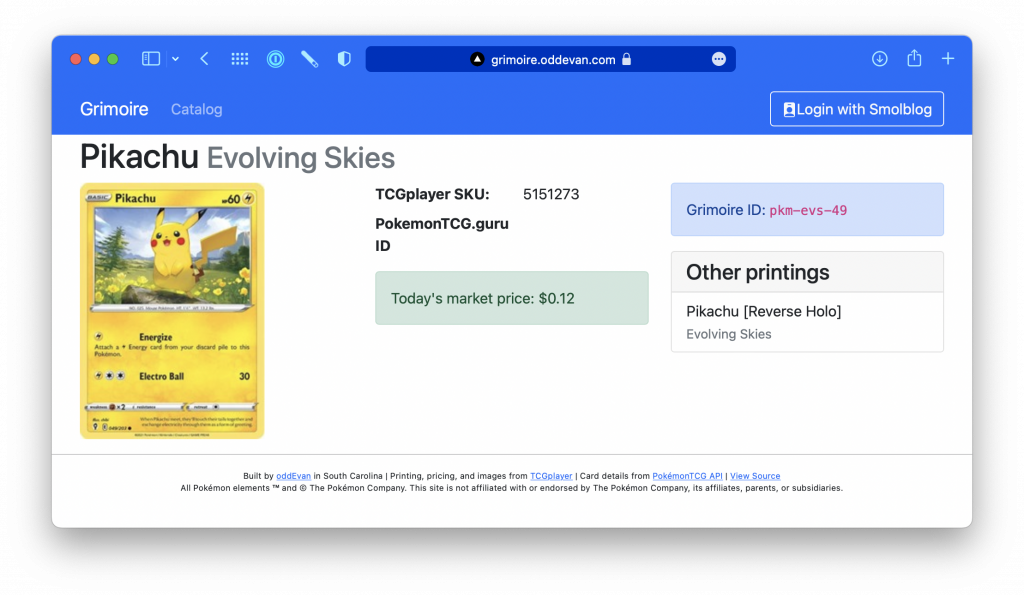
Different card, different price, but same text. The two versions of this card link to each other. This is largely in place so that, in the future, it can be easier to find out which cards you have as you're building a deck. Some desirable cards may have more inexpensive versions. That's why it was important for this feature not just to work within a set, as shown for the Pikachu card, but between different sets.
One of the headline cards for Evolving Skies was Umbreon VMAX, shown in this screenshot:
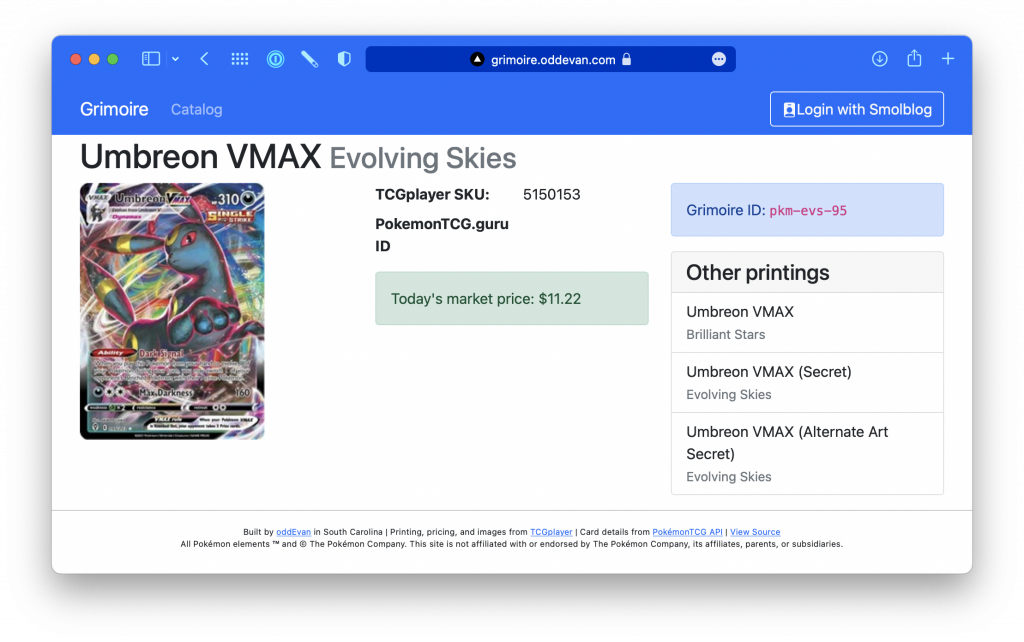
There was also a "secret" version of this card with alternate artwork:
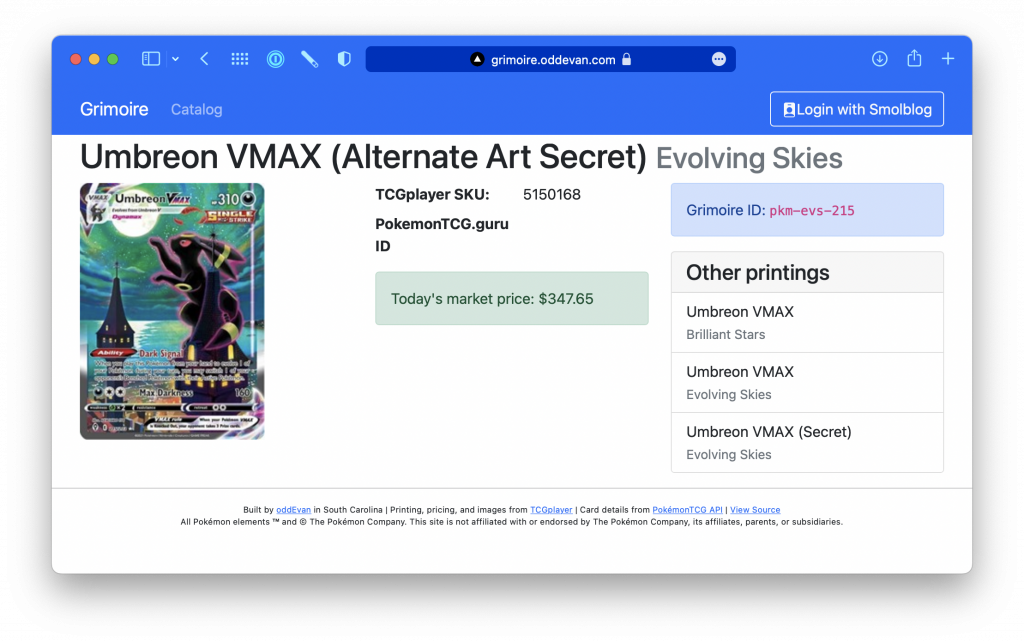
Very cool! And very expensive. But that wasn't the last time they printed this card. In the Brilliant Stars set, there is a special collection called the Trainer Gallery featuring Pokémon posing with their trainers. And here's the gigantic Umbreon:
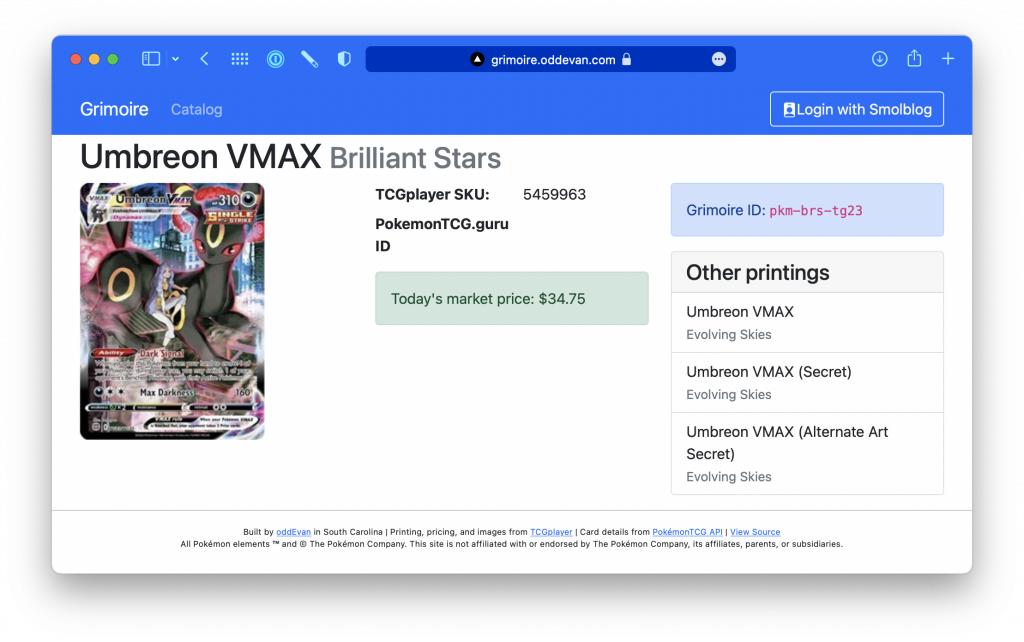
All three of these are different cards with (very!) different prices. But when building a deck, all three are functionally the same.
Personal Collections
But I set out to build a personal catalog, not just a list. So once I've logged in, how does that change things?
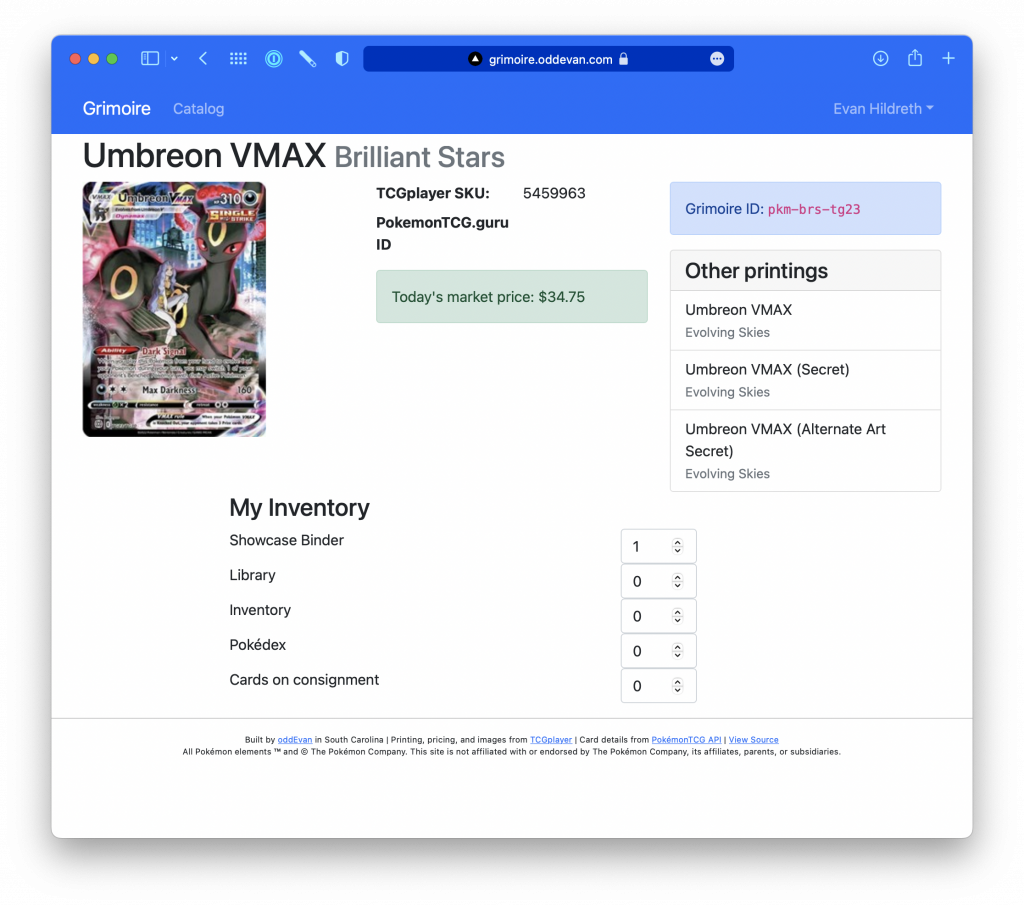
At the bottom of each card's page, there is a list of the different collections I've made. I can change the quantity of this card in each of those collections. In this case, it's a pretty rare card, so I've only got one.
On my profile page, I can see all my collections and the current value of those cards:
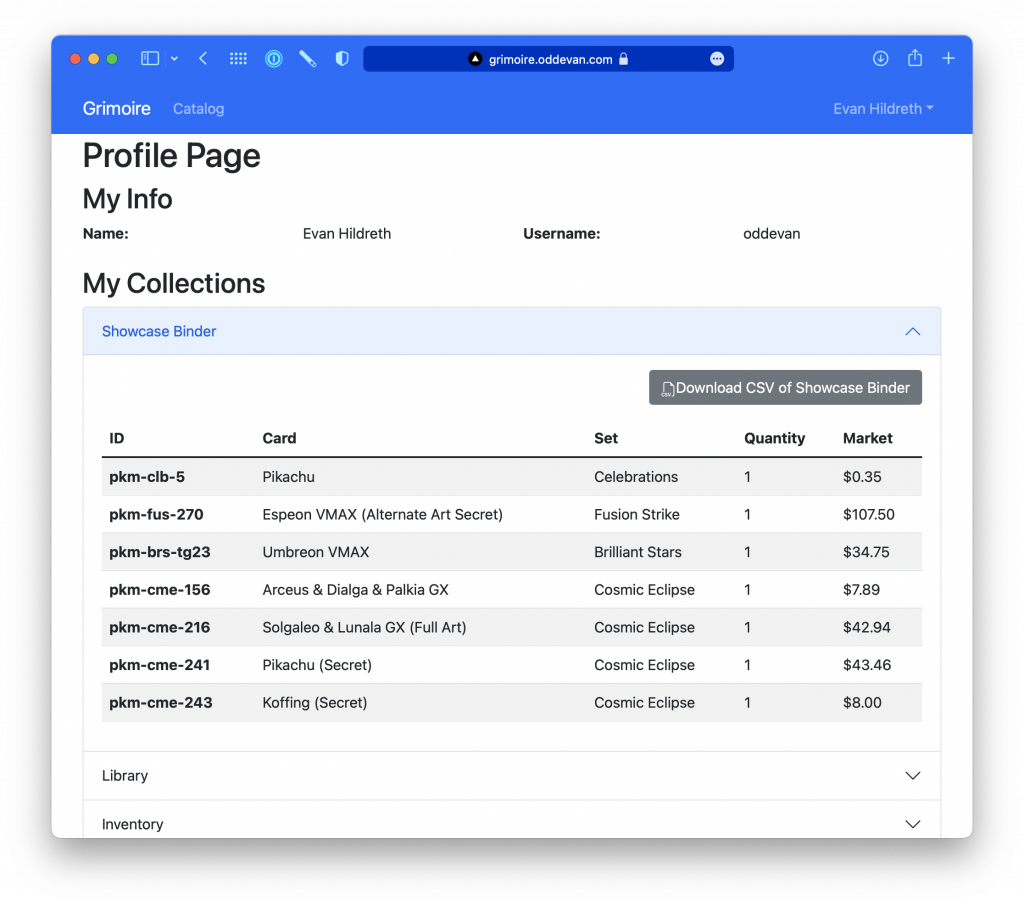
And because entering this data can take a long time, it was important for me to have a CSV export so that I can download my cards and their quantities in a standard format.
Tech Specs
I could write several blog posts about the tech problems I solved making this app. And in fact, I probably will, sometime in the next... time. If you want to see a writeup on any of the features, leave a comment!
At a high level, the frontend website is a fully static Next.js application. This means that the website is written in React and TypeScript with anything that can be rendered ahead of time written to static HTML. It's currently hosted on Vercel, but I could just as easily host it anywhere else because, again, it's static HTML. If Geocities was still around, I could host it there.
That would be a bad idea, I would not host it there.
The backend is a WordPress theme hosted on Smolblog. Remember that? The static rendering uses GraphQL to get the cards and sets, while the more interactive features use custom endpoints in the WordPress REST API. The only reason for the separation is... that... I couldn't figure out how to make the custom endpoints I wanted in GraphQL and I didn't feel like taking the time to learn it just yet.
But there were plenty of fun problems I did solve, including
- Excluding browser-only Javascript from static rendering in Next
- Setting up OAuth so that it works with WordPress multisite correctly
- Writing TypeScript types for a React component that didn't include them
- Using basic card data and an MD5 hash to find different printings
- Store authentication credentials in a cookie
- Use React context to access authentication details throughout the application
- Set up custom tables in WordPress and use them with the REST API and GraphQL
The Future
As I get to the end of the first version of this project, I learned an important lesson:
WordPress was a bad choice.
I don't say that lightly. I've spent the last few years of my life immersed in the WordPress world, and I truly believe it can be used for almost anything.
But in the case of Grimoire, the data does not lend itself to custom post types as easily as custom tables. While sets and cards could conceivably be custom post types, they would rely heavily on custom metadata and taxonomies. The data is much more suited for a traditional relational database. At this point in the project, WordPress is only being used for authentication and as an administration tool. For the future of Grimoire, the benefits of a fully-featured platform like WordPress are outweighed by the difficulties in working directly with the database.
I have a few plans for Grimoire moving forward:
- Rewrite backend in a modern framework like Laravel or Ruby on Rails. This will making with the database much easier.
- Consider using Next.js' server-side capabilities. This could take some pressure off of the backend by moving some functionality closer to the edge.
- Add detailed card information. This will only need to be stored once per printing and can enable some fun features like finding recent cards that work well together.
- Sync inventory to TCGplayer. I'd love to use Grimoire to manage my inventory that I have for sale.
- Offer a "Pro" subscription with access to historical pricing data and store inventory management. Because the people most willing to pay for something are the ones making money.
I've rambled long enough. Go check out Grimoire and let me know what you think!